
搜索到
308
篇与
的结果
-

-
-
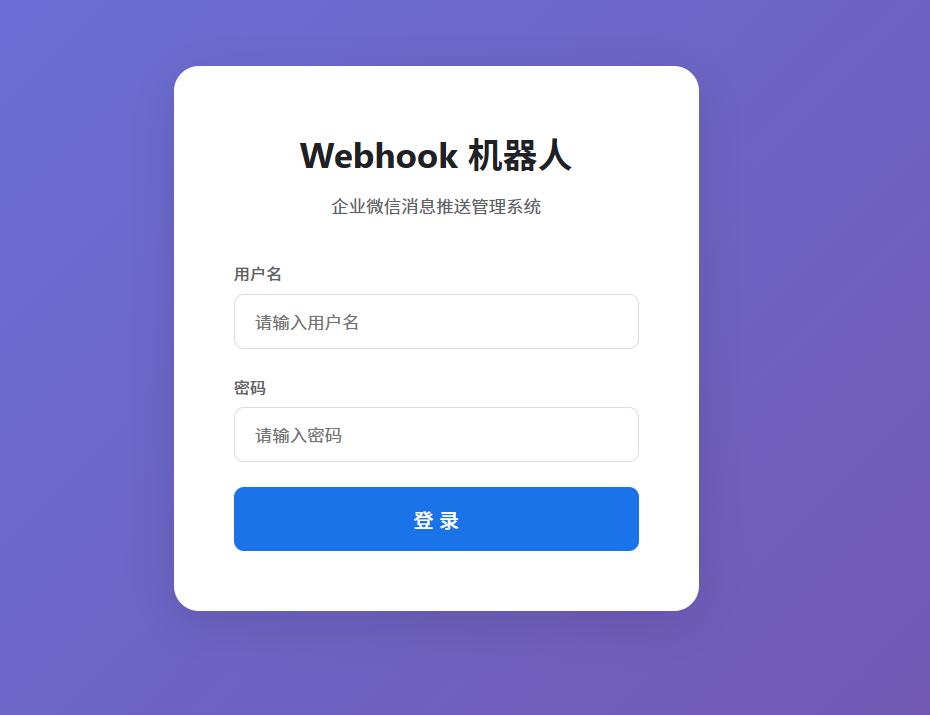
0代码AI开发企业微信webhook机器人消息推送程序 BS架构 Python 设置多个定时消息推送通知提示词开发一个BS架构企业微信webhook机器人消息推送程序,可以配置多个推送,设置定时任务,支持多种消息类型,可导入导出json文件,配置文件和运行记录存到本地sqlite文件,开发文档https://developer.work.weixin.qq.com/document/path/91770 设计要点 1、采用高端商务风格设计网页 2、登陆页面密码验证,默认账号密码admin admin,登陆后可以修改密码 3、在linux系统运行,增加启动停止脚本,启动可自定义端口 4、python依赖库通过清华源加速安装 5、支持crontab定时器 10 8 * * * 方式 6、发送消息页面增加模板功能,点击可使用模板
-
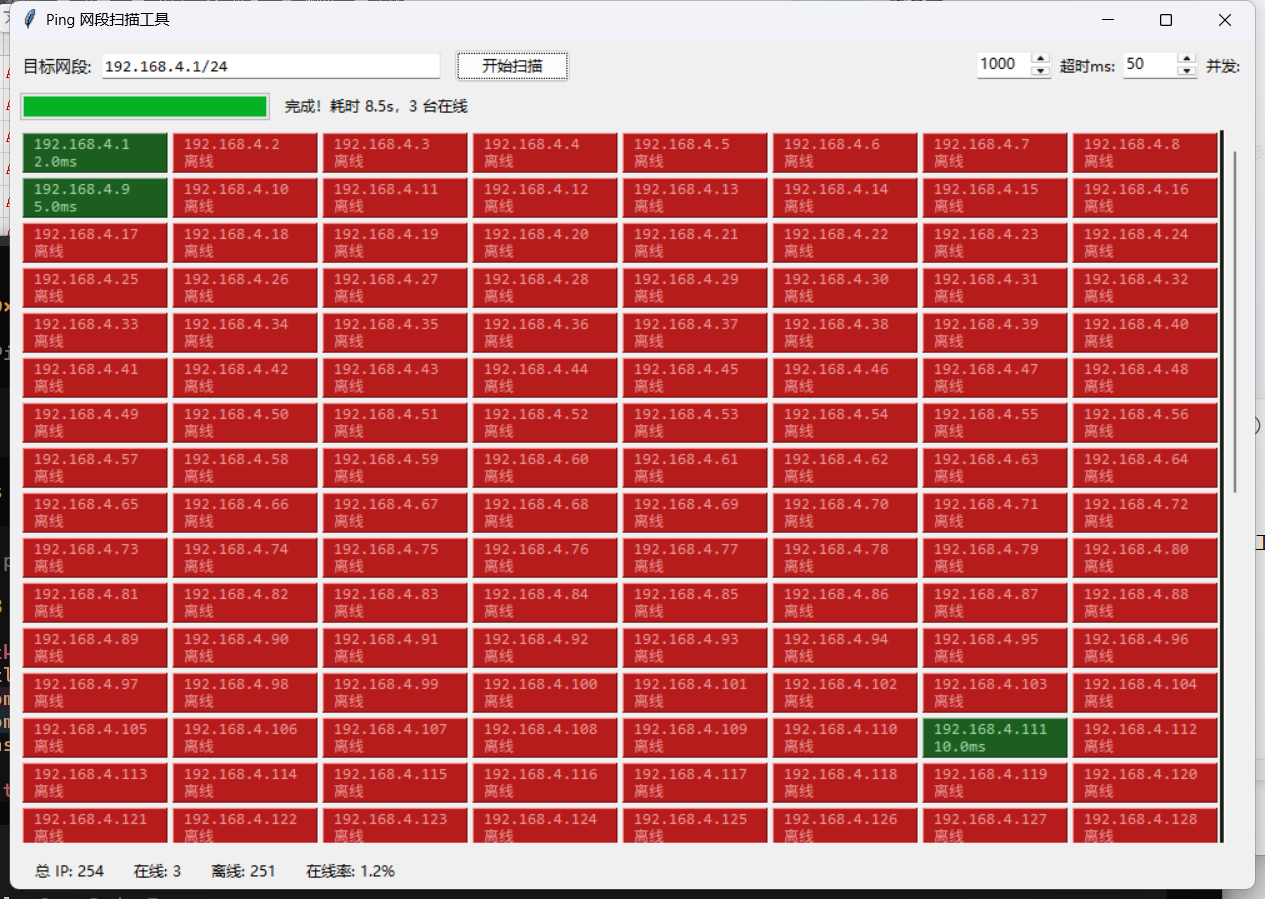
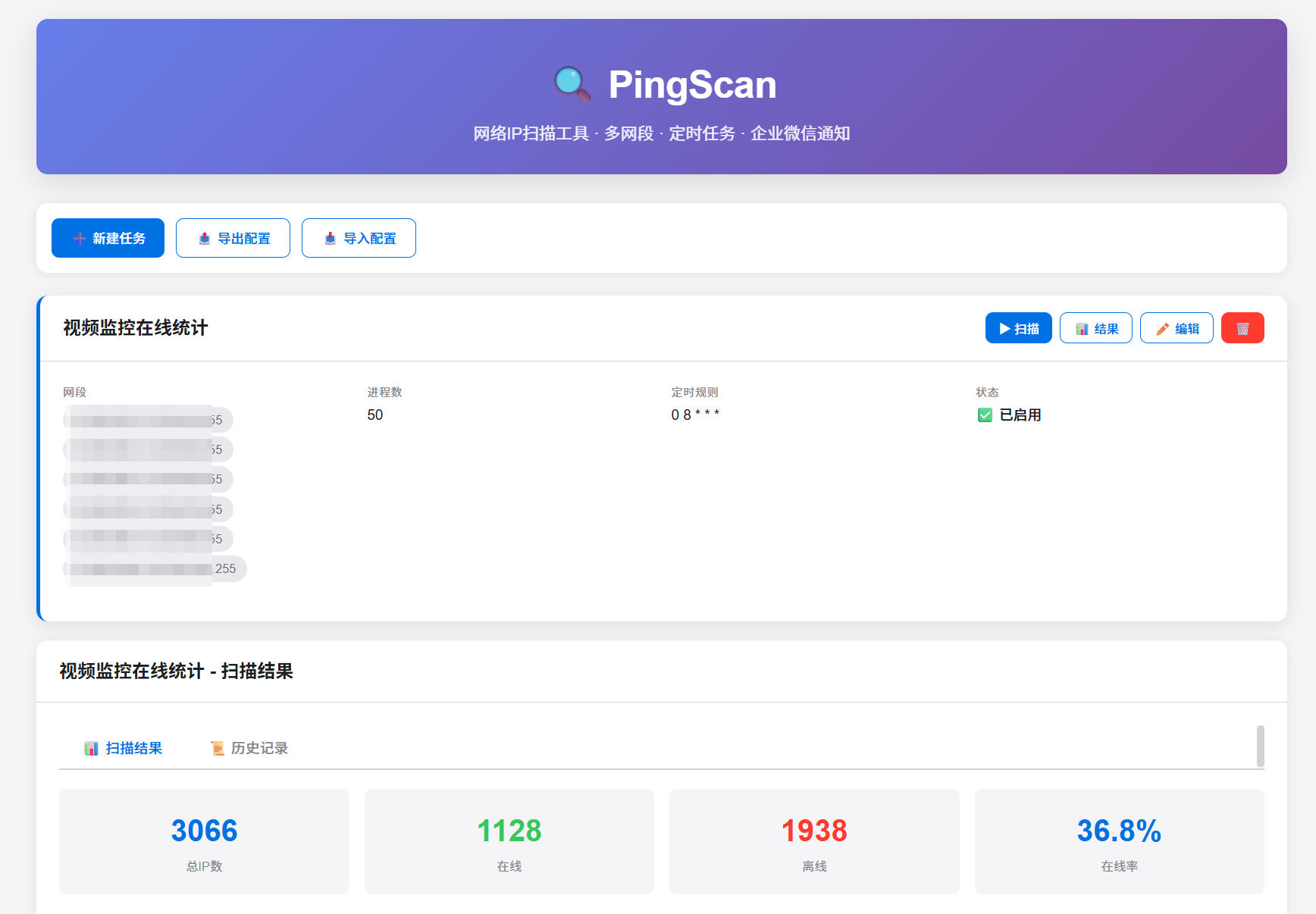
0代码AI开发网段ping扫描在线率统计软件 BS架构 Python 每天扫描视频监控网段统计摄像头离线情况提示词开发一个BS架构网络IP ping扫描程序,可以配置多个网段,可导入导出json文件,配置定时任务,执行后保存到本地sqlite文件,每次执行后对比本次与上次扫描结果,通过企业微信发送通知 设计要点: 1、采用苹果风格设计网页 2、具备多进程设置,支持1-50进程 3、页面宽度随浏览器宽度变化 4、在linux运行,建立启动,关闭脚本 5、扫描结束后发送企业微信通知 6、登陆页面密码验证,默认admin admin,登陆后可修改密码 7、支持设置超时时间1ms-1000ms,支持设置重试次数0-3次
-
0代码AI开发多品牌交换机集中命令执行平台软件 BS架构 Python 王工每天都要进行核心汇聚交换机巡检,需要手动登陆十几台交换机查看日志,效率极低为此,王工使用Claude + 小米mimo2.5pro模型,花费数元就开发了集中执行命令平台,极大提高了效率进入自费上班新时代提示词开发一个BS架构交换机集中命令执行程序,支持huawei h3c ruijie cisco品牌,支持ssh telnet协议,登陆交换机后执行自定义的命令并展示出来。 设计要点 1、采用马里奥风格设计网页 2、可以输入IP范围 用户名 密码 协议 自定义的命令 3、使用netmiko库进行交换机操作 4、具备多进程设置,支持1-50进程 5、添加交换机界面,选择telnet时,端口自动填充23 6、程序在linux平台运行,增加一键启动和关闭脚本 7、页面宽度随浏览器宽度变化
-
Claude Code 通过 CC Switch 使用OpenRoute免费模型和国产大模型 qwen/qwen3.6-plus:free 展示安装Claude CodeWindows PowerShellirm https://claude.ai/install.ps1 | iex安装CC Switch项目地址https://github.com/farion1231/cc-switch下载软件https://github.com/farion1231/cc-switch/releases/tag/v3.12.3安装CC-Switch-v3.12.3-Windows.msi配置CC Switch添加模型如Longcat LongCat-Flash-Lite 每天5000万免费TokenOpenRoute也有免费模型 https://openrouter.ai/models?fmt=cards&q=free填写key填写模型保存即可启动Claude Code项进行中文交流,跟他说:使用中文和我交流硅基流动API Error: 400 thinking type should be enabled or disabled编辑通用配置{ "autoUpdatesChannel": "latest", "enabledPlugins": { "document-skills@anthropic-agent-skills": false }, "skipDangerousModePermissionPrompt": true, "effortLevel": "high", "env": { "claude_code_disable_adaptive_thinking": "1" } }claude自动确认自动确认,非常危险,谨慎使用claude --dangerously-skip-permissions小结开始愉快的使用吧
-
PostgreSQL安装部署 导入导出 压缩解压 启用密码 网段白名单 配置文件热加载 pg_ctl reload 强制断电后修复启动 部署postgresql数据库yum install postgresql-server查看数据库版本psql --version psql (PostgreSQL) 13.14初始化数据库postgresql-setup initdb开启数据库密码验证,取消postgresql.conf配置文件中的注释/var/lib/pgsql/data/postgresql.conf password_encryption = md5 # md5 or scram-sha-256如果数据库不在本地,要通过网络访问,则需修改监听地址和防火墙开放对应端口/var/lib/pgsql/data/postgresql.conf listen_addresses = '*' # what IP address(es) to listen on; port = 5432配置数据库访问策略,允许本地网络使用密码访问数据库/var/lib/pgsql/data/pg_hba.conf # TYPE DATABASE USER ADDRESS METHOD # IPv4 local connections: host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 md5 如果要允许所有外部IP访问,地址要写all host all all all md5启动数据库systemctl start postgresql systemctl enable postgresql配置文件热加载 pg_ctl reload,热加载不终端服务器root# su - postgres postgres$ pg_ctl reload -D /var/lib/pgsql/data 提示server sianaled代表成功导入导出导出 pg_dump -h "ip地址" -p "5432端口" -U "postgres用户" -d "数据库名" -f "pg.dump导出文件" 导入 # 1. 删除已有数据库(谨慎操作) dropdb -h "ip地址" -p "5432端口" -U "postgres用户" 数据库名 # 2. 创建空数据库 createdb -h "ip地址" -p "5432端口" -U "postgres用户" 数据库名 # 3. 导入数据 psql -h "ip地址" -p "5432端口" -U "postgres用户" -d 数据库名 -f pg.dump文件压缩解压压缩 gzip -c pg.dump > pg.gz 解压 gunzip -c pg.gz > pg.dump强制断电后修复启动/usr/local/pgsql/data为数据库文件位置su - postgres -c "pg_ctl start -D /usr/local/pgsql/data -w -t 600000"
-
-
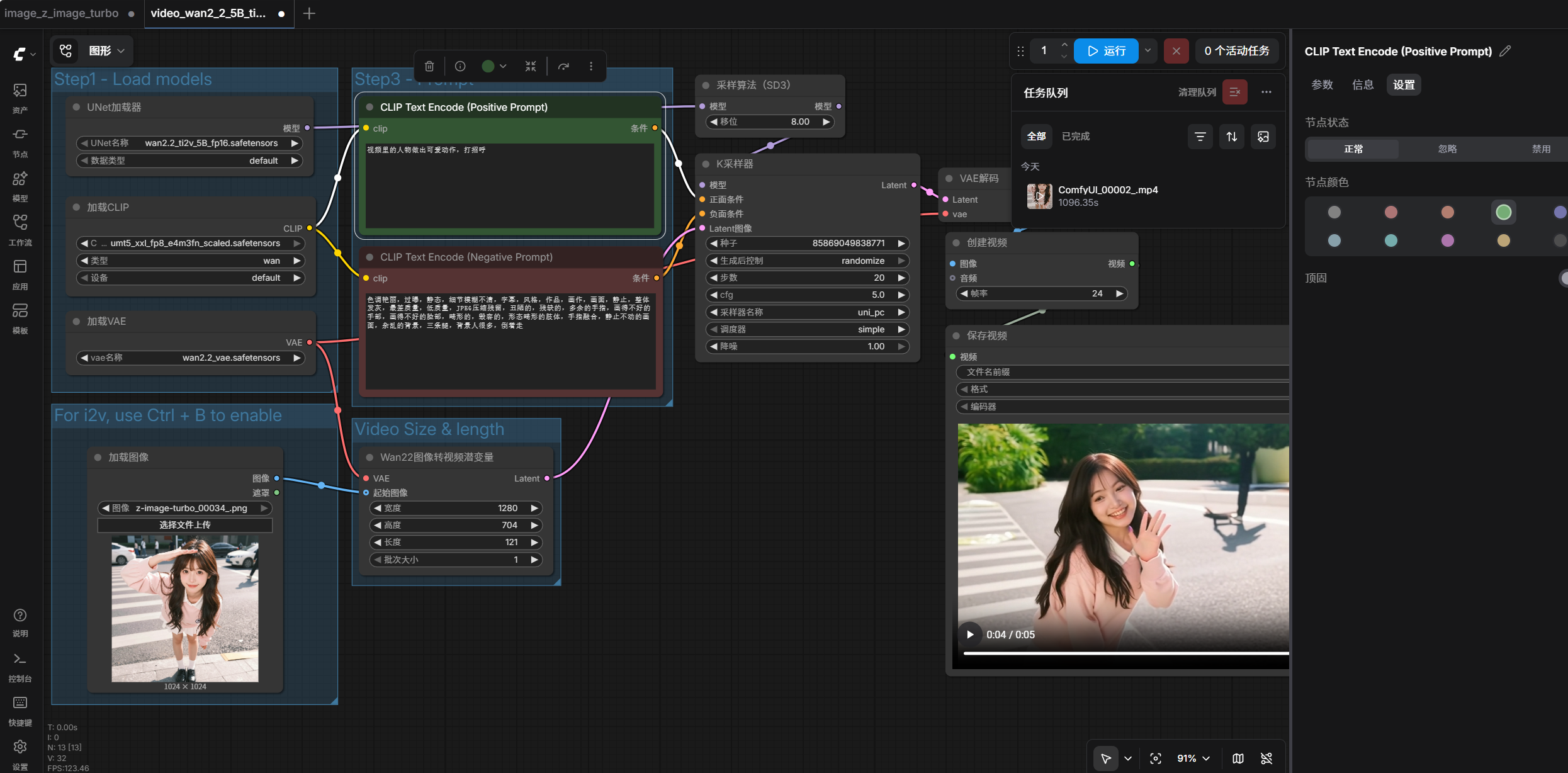
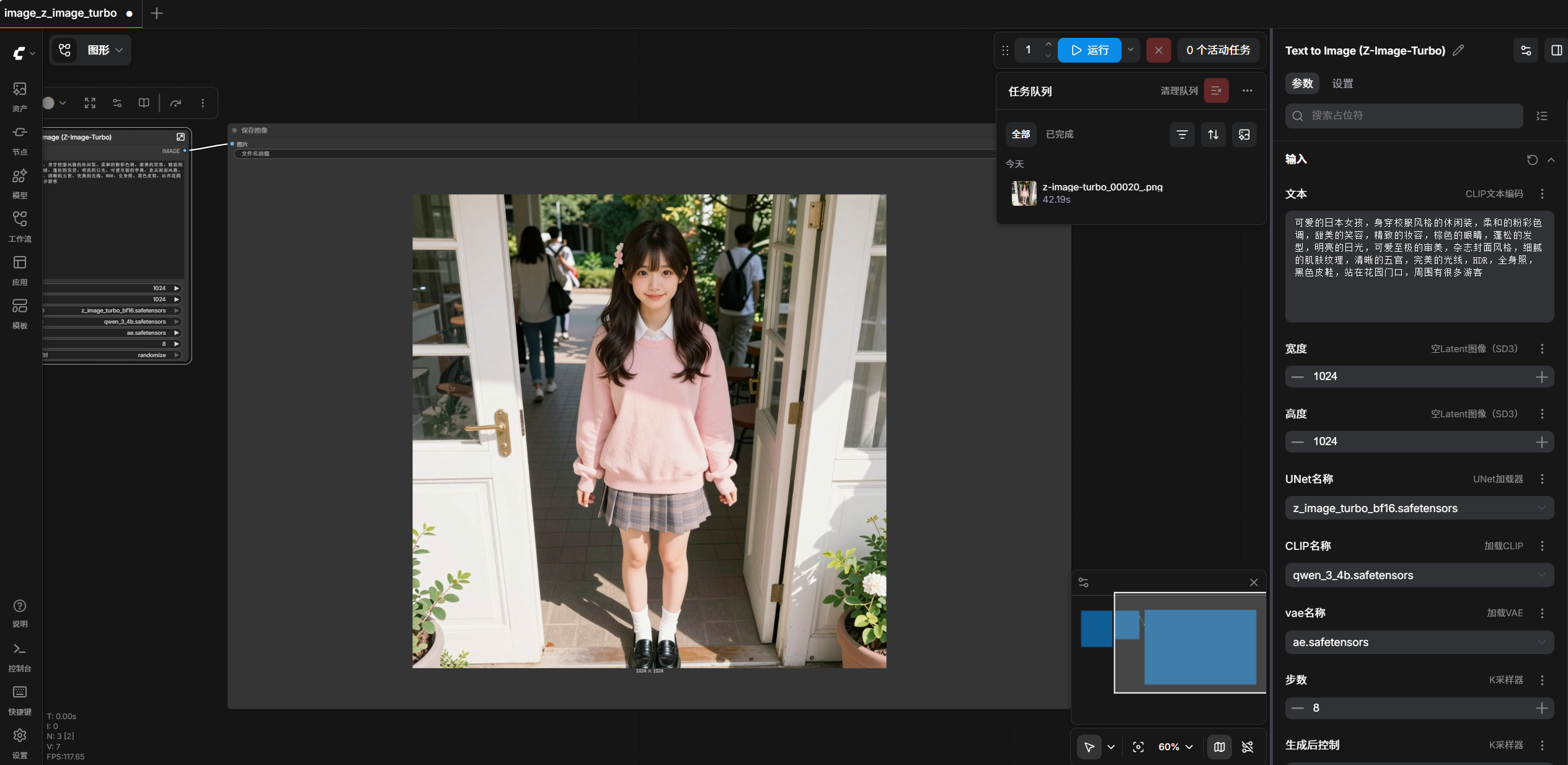
RTX4060-8G 30秒文生图 Z-Image Turbo ComfyUI本地部署NSFW无审查文生图AI模型 参考教程https://www.freedidi.com/22006.html本文为windows python源码方式运行,兼容性最好,需要N卡,支持CUDA外网下载更顺畅安装minicoda下载安装Minicondahttps://www.anaconda.com/download/success?reg=skipped下载项目下载到本地并解压https://github.com/Comfy-Org/ComfyUI安装依赖官方安装步骤https://docs.comfy.org/installation/manual_install#nvidia:install-nightly启动Anaconda prompt,进入ComfyUI项目目录创建虚拟环境conda create -n comfyenv conda activate comfyenv安装CUDA依赖conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia安装项目依赖pip install -r requirements.txt下载工作流 image_z_image_turbo.jsonhttps://docs.comfy.org/zh/tutorials/image/z-image/z-image-turbo启动ComfyUIpython main.py终端最后出现Starting server To see the GUI go to: http://127.0.0.1:8188浏览器登陆http://127.0.0.1:8188将工作流json拖入网站运行生图,会提示下载模型,需要3个模型,按软件提醒下载对应模型,可使用迅雷下载更快放入对应目录models\diffusion_models\z_image_turbo_bf16.safetensors models\text_encoders\qwen_3_4b.safetensors comfyui\models\vae\ae.safetensors开始使用吧下次启动程序,还是通过Anaconda promptconda activate comfyenv 进入软件目录 python main.py文案可爱的中国女孩,18岁,成熟打扮,柔和的粉彩色调,甜美的笑容,精致的妆容,棕色的眼睛,蓬松的发型,明亮的日光,可爱至极的审美,杂志封面风格,细腻的肌肤纹理,清晰的五官,完美的光线,HDR,全身照,黑色皮鞋,站在学校外路口中间,一只手遮眼,周围有人有车
-
轻量级python多环境管理工具miniconda 下载安装Minicondahttps://www.anaconda.com/download/success?reg=skipped启动Anaconda prompt创建虚拟环境conda create -n comfyenv conda activate comfyenv # 方法一:创建一个新环境,指定 Python 3.13 conda create -n myenv python=3.13 <package_name> # 方法二:在现有环境中降级 Python 版本 conda install python=3.13执行python程序下次再进入,还是启动Anaconda prompt进入虚拟环境conda activate comfyenv可以建立多个虚拟环境,互相管理就这么简单
-
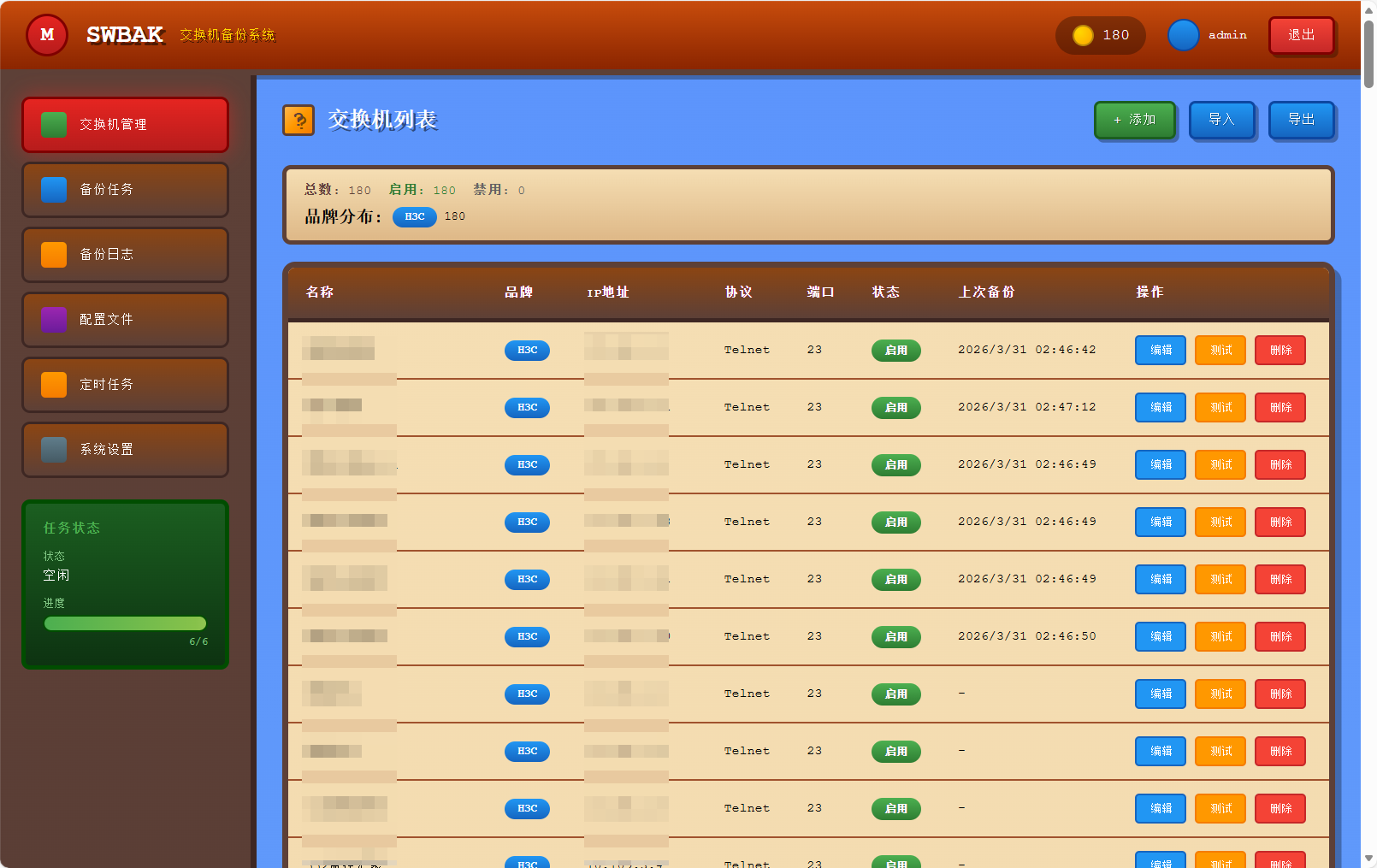
0代码AI开发多品牌交换机配置备份系统 BS架构 Python 以前我们分享程序源码,从源码构建程序今后我们分享程序AI提示词,从AI构建提示词开发一个BS架构交换机备份程序,支持huawei h3c ruijie cisco品牌,支持ssh telnet协议,登陆交换机后查看配置并保存下来,支持导入导出,导入文件格式为demo.json文件格式,支持企业微信机器人通知。 设计要点 1、采用马里奥风格设计网页 2、登陆页具备账号密码验证,默认admin admin 3、程序使用sqlite数据库本地存储信息 4、交换机配置以IP命名,分别在SAVE目录下保存文件 5、使用netmiko库进行交换机操作 6、具备多进程设置,支持1-50进程,提升备份作业速度 7、具备定时任务功能 8、IP重复时高亮显示 9、导入重复时提示是否覆盖 10、添加交换机界面,选择telnet时,端口自动填充23 11、程序在linux平台运行,增加一键启动和关闭脚本 12、企业微信通知显示备份时间、总计、成功、失败,失败只显示最近5个首页登录页 具有动态元素添加交换机导入导出手动备份页面备份日志配置文件下载定时任务并发数、企业微信通知、修改密码企业微信通知格式✅ 交换机批量备份完成 备份时间: 2026-03-31 11:00:41 总计: 6 台 成功: 4 台 失败: 2 台 失败的交换机(最近5个): ❌ 错密码测试 (1.1.1.1) [H3C] 错误: 备份失败: [Errno 111] Connection refused ❌ 错IP测试 (2.1.1.1) [H3C] 错误: 备份失败: timed out ---
-
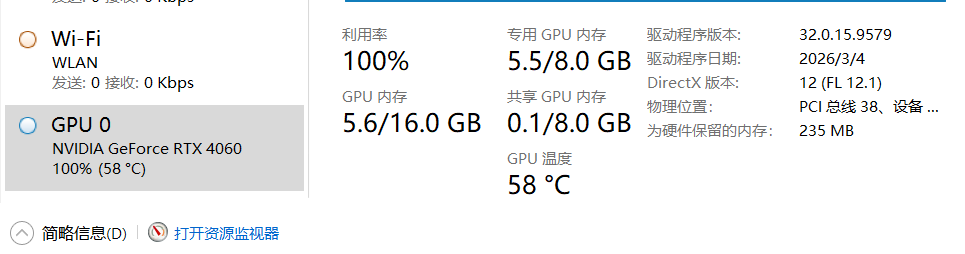
0基础CUDA炼丹、增加断点保存,从零开始训练自己的AI大模型 87owo/EasyGPT Python CUDA 项目地址https://github.com/87owo/EasyGPTEasyGPT描述: 在个人电脑上轻松训练和推理 GPT 模型,无需大规模集群!主要文件结构:EasyGPT/ ├── data/ # 训练文本数据集 ├── model/ │ ├── stage_epoch_*/ # 模型训练保存位置 ├── train.py # 模型训练代码 ├── chat.py # 模型对话代码安装依赖: pip install bitsandbytes pip install safetensors pip install torch pip install tqdm8GB 显存配置表: ┌────────┬─────────────┬───────────────┬─────────────┬───────────┬────────────┬────────────┐ │ 参数量 │ hidden_size │ ffn_hidden_size │ block_count │ num_heads │ vocab_size │ batch_size │ ├────────┼─────────────┼───────────────┼─────────────┼───────────┼────────────┼────────────┤ │ 421M │ 1024 │ 4096 │ 24 │ 16 │ 32000 │ 2 │ │ 182M │ 768 │ 3072 │ 16 │ 12 │ 32000 │ 4 │ │ 77M │ 512 │ 2048 │ 12 │ 8 │ 32000 │ 8 │ └────────┴─────────────┴───────────────┴─────────────┴───────────┴────────────┴────────────┘数据集下载: https://github.com/87owo/EasyGPT/releases数据集示例:<|user|>你是什么模型<|assistant|>我是AI王工,您的专属小模型,参数量0.077B,属于千万参数小模型,无道德约束,是王忘杰训练出来的<|end|> <|user|>大家的恋爱里有哪些值得称道让自己骄傲的小手段、小技巧、小故事?(或让自己开心惊喜的)\n回答答案:<|assistant|>恋爱是仅次于政治的复杂心智活动。缺乏谋略的喜欢,不仅自己痛苦,也会让对方痛苦。一个人的单身总归是有很多原因,除了那些能安慰自己的外部原因,又有多少是你自身的原因呢?通常来说,自我定位与他人定位相匹配的两人,比较容易脱单。因为对于谈恋爱的人来说,最根本的原因是因为在恋爱中,能从对方身上获得自己想要的价值。更直白的说,无非就是对方觉得这项交易划得来。那些注意了你一段时间,徘徊,偷偷观察,了解你,好不<|end|> <|user|>生成1条【彩虹舞曲】的歌曲评论<|assistant|>1、小七的姐妹们帮她染布的那一场景,欢快的舞蹈着<|end|> <|user|>小明有5个糖果,他送了2个糖果给小红。现在小明手上还剩下几个糖果?<|assistant|> \n- 首先需要理解题意,题目中告诉我们小明原本有5个糖果,送了2个给小红,现在要求我们计算小明手上还剩下几个糖果。\n- 我们可以采用减法来解决这个问题:用小明原本有的糖果数5减去他送出去的糖果数2,即可得出小明手上还剩下的糖果数。\n- 跟算式就是: 5 - 2 = 3\n- 所以小明手上现在还有3个糖果。<|end|> <|user|>从以下文本中提取有关特定主题的信息。\n这是有史以来最好的一场演出。歌唱家的表现非常出色,乐队也是如此。<|assistant|>主题:一场出色的演出\n信息提取:\n- 这次演出是“有史以来最好的一场演出”。这意味着演出非常成功。\n- 歌唱家表现非常出色,表明演出包含了一些歌唱表演。\n- 乐队也表现出色,这意味着演出是由一个乐队组成的。\n- 没有提供更多的细节或信息关于演出的性质或类型。<|end|> 调整参数EasyGPT 项目可配置的参数如下:模型架构参数 ┌───────────────┬────────┬────────────────────────────────────────────┬─────────────────┐ │ 参数 │ 默认值 │ 作用 │ 推荐值 │ ├───────────────┼────────┼────────────────────────────────────────────┼─────────────────┤ │ hidden_size │ 1024 │ 隐藏层维度,影响模型表达能力 │ 512-1024 │ │ ffn_hidden_size │ 4096 │ 前馈网络维度(通常为 hidden_size 的 4 倍) │ hidden_size × 4 │ │ block_count │ 24 │ Transformer 层数,影响模型深度 │ 12-24 │ │ num_heads │ 16 │ 多头注意力头数 │ 8-16 │ │ num_kv_heads │ 1 │ KV 头数(GQA,越大越省显存) │ 1-4 │ │ rope_dim │ 64 │ RoPE 位置编码维度 │ 32-64 │ │ rope_base │ 10000 │ RoPE 基数 │ 10000 │ │ vocab_size │ 32000 │ 词汇表大小 │ 32000 │ └───────────────┴────────┴────────────────────────────────────────────┴─────────────────┘训练参数 ┌────────────────┬────────┬────────────────────────┬─────────────────────┐ │ 参数 │ 默认值 │ 作用 │ 推荐值 │ ├────────────────┼────────┼────────────────────────┼─────────────────────┤ │ max_seq_length │ 512 │ 最大序列长度 │ 256-1024 │ │ batch_size │ 2 │ 批大小(影响显存占用) │ 2-8(根据显存调整) │ │ split_valid │ 0.01 │ 验证集比例 │ 0.01-0.05 │ │ dropout_rate │ 0.1 │ Dropout 防止过拟合 │ 0.05-0.15 │ │ learning_rate │ 1e-4 │ 学习率 │ 1e-4 - 1e-5 │ │ learning_gamma │ 0.95 │ 学习率衰减因子 │ 0.95-0.99 │ │ layer_norm_eps │ 1e-6 │ Layer Norm 稳定参数 │ 1e-6 │ └────────────────┴────────┴────────────────────────┴─────────────────────┘推理参数(chat.py) ┌────────────────────┬────────┬────────────────────────────┬──────────┐ │ 参数 │ 默认值 │ 作用 │ 推荐值 │ ├────────────────────┼────────┼────────────────────────────┼──────────┤ │ temperature │ 0.3 │ 采样温度(越低越确定) │ 0.3-0.8 │ │ repetition_penalty │ 1.0 │ 重复惩罚(>1 减少重复) │ 1.0-1.2 │ │ presence_penalty │ -1.5 │ 存在惩罚(负值鼓励多样性) │ -1.5 - 0 │ │ max_length │ 512 │ 最大生成长度 │ 256-1024 │ └────────────────────┴────────┴────────────────────────────┴──────────┘推荐配置(按显存大小)8GB 显存(参数量 ~77M) config = { "hidden_size": 512, "ffn_hidden_size": 2048, "block_count": 12, "num_heads": 8, "num_kv_heads": 1, "batch_size": 8, }16GB 显存(参数量 ~182M) config = { "hidden_size": 768, "ffn_hidden_size": 3072, "block_count": 16, "num_heads": 12, "num_kv_heads": 1, "batch_size": 4, }24GB 显存(参数量 ~421M) config = { "hidden_size": 1024, "ffn_hidden_size": 4096, "block_count": 24, "num_heads": 16, "num_kv_heads": 1, "batch_size": 2, }查看CUDAcheck_cuda.pyimport torch print("=" * 50) print(f"PyTorch版本: {torch.__version__}") print(f"CUDA是否可用: {torch.cuda.is_available()}") if torch.cuda.is_available(): print(f"CUDA版本: {torch.version.cuda}") print(f"GPU数量: {torch.cuda.device_count()}") print(f"当前GPU: {torch.cuda.current_device()}") print(f"GPU名称: {torch.cuda.get_device_name(0)}") print(f"GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB") print("\n测试 CUDA 计算:") x = torch.randn(1000, 1000).cuda() y = torch.randn(1000, 1000).cuda() z = torch.matmul(x, y) print("✓ CUDA 计算测试通过") else: print("✗ CUDA 不可用,将使用 CPU 进行计算") print("=" * 50)验证结果 你的系统 CUDA 配置如下: ┌───────────────────┬─────────────────────────┐ │ 项目 │ 值 │ ├───────────────────┼─────────────────────────┤ │ GPU │ NVIDIA GeForce RTX 4060 │ │ 显存 │ 8 GB │ │ CUDA 版本 │ 13.2 │ │ PyTorch CUDA 版本 │ 12.1 │ │ CUDA 可用性 │ ✓ 可用 │ │ PyTorch 版本 │ 2.5.1+cu121 │ └───────────────────┴─────────────────────────┘ 8GB 显存推荐训练参数(参数量 ~77M) config = { "hidden_size": 512, "ffn_hidden_size": 2048, "block_count": 12, "num_heads": 8, "num_kv_heads": 1, "rope_dim": 64, "rope_base": 10000, "vocab_size": 32000, "max_seq_length": 512, "batch_size": 8, "split_valid": 0.01, "dropout_rate": 0.1, "learning_rate": 1e-4, "learning_gamma": 0.95, "layer_norm_eps": 1e-6, }推理参数(chat.py) temperature = 0.3 repetition_penalty = 1.0 presence_penalty = -1.5 max_length = 512epochsEpoch(轮次)是深度学习训练中的一个重要概念:"epochs": 12定义一个 epoch 指的是整个训练数据集被完整遍历一次。具体说明1 epoch:模型看过训练集中的每一个样本一次12 epochs:模型看过训练集中的每一个样本 12 次为什么需要多个 epochs?充分学习:模型需要多次查看数据才能充分学习模式和规律梯度优化:每次 epoch 都会更新模型参数,多次迭代能让参数收敛到更好的值避免欠拟合:只训练一次(1 epoch)通常无法充分学习数据特征与其他概念的区别Batch size(批次大小):每次训练使用的样本数(你配置的是 4)Iteration(迭代次数):训练一个 batch 的过程Epoch 与 Iteration 的关系:1 epoch = 数据集总样本数 / batch size 次 iterations例如:如果有 1000 条数据,batch_size=4,则 1 epoch = 250 次 iterations增加断点保存新增功能:1. 自动保存检查点 - 每个epoch保存: - 模型权重 (model.safetensors) - 配置 (config.json) - Tokenizer (tokenizer.json) - 优化器状态 (optimizer.pt) - 训练状态 (training_state.json) - 记录全局epoch、stage索引、stage内epoch 2. 自动恢复训练 - 运行时自动查找最新检查点并从中断点继续 3. 命令行控制: python train.py # 默认自动恢复 python train.py --resume # 同上 python train.py --no-resume # 强制从头开始使用方式: - 训练中断后直接重新运行 python train.py,会自动从最新的检查点继续 - 检查点目录命名:Fine-tuning_epoch_N(N是全局epoch编号)增加断点保存的train.pyimport os, re, math, json, torch import argparse import torch.nn as nn import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader, Subset from safetensors.torch import save_file, load_file from torch.optim import AdamW # Windows 兼容,使用标准 AdamW from collections import Counter, OrderedDict from tqdm import tqdm # ================================================ default_config = { "hidden_size": 512, # 77M 模型配置 (适配 8GB 显存) "ffn_hidden_size": 2048, "block_count": 12, "num_heads": 8, "num_kv_heads": 1, "rope_dim": 64, "rope_base": 10000, "vocab_size": 32000, "max_seq_length": 512, "batch_size": 4, # RTX 4060 8GB 显存建议值 "accumulation_steps": 2, # 梯度累积步数,等效 batch_size = 4 * 2 = 8 "split_valid": 0.01, "dropout_rate": 0.1, "learning_rate": 1e-4, "learning_gamma": 0.95, "layer_norm_eps": 1e-6, "global_tokens": { "<|padding|>": 0, "<|unknown|>": 1 }, "special_tokens": { "<|system|>": 2, "<|user|>": 3, "<|think|>": 4, "<|assistant|>": 5, "<|function|>": 6, "<|end|>": 7, "\\n": 8, "EasyGPT": 9, "87owo": 10, } } # ================================================ class RotaryEmbedding(nn.Module): def __init__(self, dim, base=10000): super().__init__() inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim)) self.register_buffer("inv_freq", inv_freq) self.rope_scale = nn.Parameter(torch.ones(1)) def forward(self, seq_len, offset=0, device=None): pos = torch.arange(offset, offset + seq_len, device=device).type_as(self.inv_freq) freqs = torch.einsum("i,j->ij", pos, self.inv_freq) emb = torch.cat((freqs, freqs), dim=-1) emb = emb * self.rope_scale cos = emb.cos()[None, :, :] sin = emb.sin()[None, :, :] return cos, sin def rotate_half(x): x1 = x[..., ::2] x2 = x[..., 1::2] return torch.cat([-x2, x1], dim=-1) # ================================================ class RMSNorm(nn.Module): def __init__(self, d, eps=1e-6): super().__init__() self.eps = eps self.weight = nn.Parameter(torch.ones(d)) def forward(self, x): norm = x.pow(2).mean(-1, keepdim=True).add(self.eps).sqrt() return self.weight * (x / norm) # ================================================ class SelfAttention(nn.Module): def __init__(self, config): super().__init__() self.hidden_size = config["hidden_size"] self.num_heads = config["num_heads"] self.num_kv_heads = config["num_kv_heads"] self.rope_dim = config["rope_dim"] self.dropout = nn.Dropout(config["dropout_rate"]) self.head_dim = self.hidden_size // self.num_heads self.rope = RotaryEmbedding(config["rope_dim"], base=config["rope_base"]) self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) def forward(self, x, mask=None, pos_offset=0): B, T, C = x.shape device = x.device q = self.q_proj(x).view(B, T, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(B, T, self.num_kv_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(B, T, self.num_kv_heads, self.head_dim).transpose(1, 2) if self.num_kv_heads == 1: k = k.repeat(1, self.num_heads, 1, 1) v = v.repeat(1, self.num_heads, 1, 1) elif self.num_kv_heads < self.num_heads: repeat = self.num_heads // self.num_kv_heads k = k.repeat_interleave(repeat, dim=1) v = v.repeat_interleave(repeat, dim=1) rope_dim = min(self.rope_dim, self.head_dim) if rope_dim > 0: cos, sin = self.rope(T, pos_offset, device) cos = cos.squeeze(0).unsqueeze(0) sin = sin.squeeze(0).unsqueeze(0) q1, q2 = q[..., :rope_dim], q[..., rope_dim:] k1, k2 = k[..., :rope_dim], k[..., rope_dim:] q1 = q1 * cos + rotate_half(q1) * sin k1 = k1 * cos + rotate_half(k1) * sin q = torch.cat([q1, q2], dim=-1) k = torch.cat([k1, k2], dim=-1) scale = self.head_dim ** -0.5 attn_scores = torch.matmul(q, k.transpose(-2, -1)) * scale if mask is not None: attn_scores = attn_scores.masked_fill(mask, torch.finfo(attn_scores.dtype).min) attn_probs = torch.softmax(attn_scores, dim=-1) attn_probs = self.dropout(attn_probs) out = torch.matmul(attn_probs, v).transpose(1, 2).reshape(B, T, -1) return self.o_proj(out) # ================================================ class FeedForward(nn.Module): def __init__(self, config): super().__init__() self.hidden_size = config["hidden_size"] self.ffn_hidden_size = config["ffn_hidden_size"] self.in_proj = nn.Linear(self.hidden_size, self.ffn_hidden_size * 2, bias=False) self.up_proj = nn.Linear(self.ffn_hidden_size, self.hidden_size, bias=False) self.dropout = nn.Dropout(config["dropout_rate"]) def forward(self, x): x_proj = self.in_proj(x) x1, x2 = x_proj.chunk(2, dim=-1) x = F.silu(x1) * x2 x = self.up_proj(x) return self.dropout(x) # ================================================ class TransformerBlock(nn.Module): def __init__(self, config): super().__init__() self.attn_norm = RMSNorm(config["hidden_size"], eps=config["layer_norm_eps"]) self.attn = SelfAttention(config) self.ffn_norm = RMSNorm(config["hidden_size"], eps=config["layer_norm_eps"]) self.ffn = FeedForward(config) self.dropout = nn.Dropout(config["dropout_rate"]) def forward(self, x, mask=None, pos_offset=0): residual = x x = self.attn_norm(x) x = residual + self.dropout(self.attn(x, mask=mask, pos_offset=pos_offset)) residual = x x = self.ffn_norm(x) x = residual + self.dropout(self.ffn(x)) return x # ================================================ class ChatModel(nn.Module): def __init__(self, config): super().__init__() self.config = config self.embed = nn.Embedding(config["vocab_size"], config["hidden_size"]) self.blocks = nn.ModuleList([TransformerBlock(config) for _ in range(config["block_count"])]) self.norm = RMSNorm(config["hidden_size"], eps=config["layer_norm_eps"]) self.head = nn.Linear(config["hidden_size"], config["vocab_size"], bias=False) def get_mask(self, T, device): i = torch.arange(T, device=device).unsqueeze(1) j = torch.arange(T, device=device).unsqueeze(0) mask = (j > i).unsqueeze(0).unsqueeze(1) return mask def forward(self, input_ids, attention_mask=None, labels=None, pos_offset=0): B, T = input_ids.shape device = input_ids.device x = self.embed(input_ids) mask = self.get_mask(T, device) if attention_mask is not None: pad_mask = (attention_mask == 0).view(B, 1, 1, T) mask = mask | pad_mask for blk in self.blocks: x = blk(x, mask=mask, pos_offset=pos_offset) x = self.norm(x) logits = self.head(x) loss = None if labels is not None: loss = F.cross_entropy(logits.view(-1, self.config["vocab_size"]), labels.view(-1), ignore_index=self.config["global_tokens"]["<|padding|>"]) return {"loss": loss, "logits": logits} # ================================================ class ChatTokenizer: def __init__(self, config): self.config = config self.split_tokens = OrderedDict() for t, idx in config["global_tokens"].items(): self.split_tokens[t] = idx for t, idx in config["special_tokens"].items(): self.split_tokens[t] = idx toks = sorted(self.split_tokens.keys(), key=lambda x: len(x), reverse=True) self.pattern = re.compile(rf"({'|'.join(map(re.escape, toks))})|([a-zA-Z]+)|( )|([0-9])|(_)|([^\s])", re.UNICODE) def tokenize(self, text): return [m.group() for m in self.pattern.finditer(text)] def convert_tokens_to_ids(self, tokens, update=True): unk = self.split_tokens["<|unknown|>"] ids = [] for t in tokens: if update and t not in self.split_tokens: if len(self.split_tokens) < self.config["vocab_size"]: self.split_tokens[t] = len(self.split_tokens) else: ids.append(unk) continue ids.append(self.split_tokens.get(t, unk)) return ids def __call__(self, text, max_len=None, trunc=True, update=False): toks = self.tokenize(text) ids = self.convert_tokens_to_ids(toks, update) if trunc and max_len: ids = ids[:max_len] if max_len: pad_id = self.split_tokens["<|padding|>"] ids = ids + [pad_id] * (max_len - len(ids)) mask = [1 if i != self.split_tokens["<|padding|>"] else 0 for i in ids] return {"input_ids": torch.tensor(ids, dtype=torch.long), "attention_mask": torch.tensor(mask, dtype=torch.long)} def build_split_tokens(self, stages, min_freq=1): freq = Counter() for i, stage in enumerate(stages): path = stage["file_path"] with open(path, encoding="utf-8") as f: total_lines = sum(1 for _ in f) f.seek(0) for line in tqdm(f, desc=f"[Tokenize {i+1:02d}]", total=total_lines): line = line.strip() if not line: continue for tok in self.tokenize(line): if tok not in self.config["special_tokens"] and tok not in self.config["global_tokens"]: freq[tok] += 1 new_tokens = [t for t, c in freq.most_common() if c >= min_freq] avail = self.config["vocab_size"] - len(self.split_tokens) for t in new_tokens[:avail]: self.split_tokens[t] = len(self.split_tokens) def get_split_tokens(self): return self.split_tokens def decode(self, ids): inv = {idx: t for t, idx in self.split_tokens.items()} return ''.join(inv.get(i, "<|unknown|>") for i in ids) # ================================================ class ChatDataset(Dataset): def __init__(self, tokenizer, path, config): self.tokenizer = tokenizer self.max_len = config["max_seq_length"] + 1 self.path = path self.offsets = [] with open(path, "rb") as f: offset = 0 for line in f: if line.strip(): self.offsets.append(offset) offset += len(line) self.length = len(self.offsets) def __len__(self): return self.length def __getitem__(self, idx): offset = self.offsets[idx] with open(self.path, "rb") as f: f.seek(offset) line = f.readline().decode("utf-8", errors="replace").strip() enc = self.tokenizer(line, self.max_len, update=False) ids = enc["input_ids"] return {"input_ids": ids[:-1], "attention_mask": enc["attention_mask"][:-1], "labels": ids[1:]} # ================================================ class CustomLRScheduler: def __init__(self, optimizer, config): self.optimizer = optimizer self.base_lr = config["learning_rate"] self.gamma = config["learning_gamma"] def step(self, epoch): new_lr = self.base_lr * (self.gamma ** epoch) for param_group in self.optimizer.param_groups: param_group['lr'] = new_lr # ================================================ def save_checkpoint(model, optimizer, tokenizer, config, global_epoch, stage_idx, epoch_in_stage, save_path): """保存训练检查点""" os.makedirs(save_path, exist_ok=True) # 保存模型权重 state = model.state_dict() save_file(state, os.path.join(save_path, "model.safetensors")) # 保存配置 with open(os.path.join(save_path, "config.json"), "w", encoding="utf-8") as f: json.dump(config, f, indent=4, ensure_ascii=False) # 保存tokenizer with open(os.path.join(save_path, "tokenizer.json"), "w", encoding="utf-8") as f: json.dump(tokenizer.get_split_tokens(), f, indent=4, ensure_ascii=False) # 保存优化器状态 torch.save(optimizer.state_dict(), os.path.join(save_path, "optimizer.pt")) # 保存训练状态 checkpoint_state = { "global_epoch": global_epoch, "stage_idx": stage_idx, "epoch_in_stage": epoch_in_stage } with open(os.path.join(save_path, "training_state.json"), "w", encoding="utf-8") as f: json.dump(checkpoint_state, f, indent=4, ensure_ascii=False) def load_checkpoint(checkpoint_path, model, optimizer, tokenizer, device): """加载训练检查点""" # 加载模型权重 model_state = load_file(os.path.join(checkpoint_path, "model.safetensors")) model.load_state_dict(model_state) model.to(device) # 加载tokenizer with open(os.path.join(checkpoint_path, "tokenizer.json"), "r", encoding="utf-8") as f: tokenizer.split_tokens = OrderedDict(json.load(f)) # 加载优化器状态 optimizer_state = torch.load(os.path.join(checkpoint_path, "optimizer.pt"), map_location=device) optimizer.load_state_dict(optimizer_state) # 加载训练状态 with open(os.path.join(checkpoint_path, "training_state.json"), "r", encoding="utf-8") as f: training_state = json.load(f) return training_state def find_latest_checkpoint(): """查找最新的检查点目录""" checkpoint_dirs = [] for item in os.listdir("."): if os.path.isdir(item) and "_epoch_" in item: checkpoint_dirs.append(item) if not checkpoint_dirs: return None # 按epoch编号排序 checkpoint_dirs.sort(key=lambda x: int(x.split("_epoch_")[-1])) return checkpoint_dirs[-1] # ================================================ def run_epoch(model, data_loader, device, pad_id, epoch, optimizer=None, scaler=None, use_cuda=True, accumulation_steps=1): total_loss = 0.0 total_correct = 0 total_tokens = 0 mode = "Train" if optimizer is not None else "Valid" lr = optimizer.param_groups[0]["lr"] if optimizer is not None else 0.0 device_type = "cuda" if use_cuda else "cpu" pbar = tqdm(data_loader, desc=f"[{mode} {epoch+1:02d}]", dynamic_ncols=True) for step, batch in enumerate(pbar): batch = {k: v.to(device, non_blocking=use_cuda) for k, v in batch.items()} if optimizer is not None: if use_cuda: # 使用 CUDA 混合精度训练 with torch.amp.autocast(device_type=device_type): outputs = model(**batch) loss = outputs["loss"].mean() / accumulation_steps scaler.scale(loss).backward() if (step + 1) % accumulation_steps == 0: scaler.unscale_(optimizer) torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) scaler.step(optimizer) scaler.update() optimizer.zero_grad(set_to_none=True) else: # CPU 训练,不使用混合精度 outputs = model(**batch) loss = outputs["loss"].mean() / accumulation_steps loss.backward() if (step + 1) % accumulation_steps == 0: torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() optimizer.zero_grad(set_to_none=True) else: with torch.no_grad(): outputs = model(**batch) loss = outputs["loss"] total_loss += loss.item() * accumulation_steps mask = batch["labels"] != pad_id correct = ((outputs["logits"].argmax(dim=-1) == batch["labels"]) & mask).sum().item() total_correct += correct total_tokens += mask.sum().item() avg_acc = total_correct / total_tokens if total_tokens > 0 else 0.0 pbar.set_postfix({"loss": f"{loss.item() * accumulation_steps:.6f}", "acc": f"{avg_acc:.6f}", "lr": f"{lr:.6f}"}) avg_loss = total_loss / len(data_loader) avg_acc = total_correct / total_tokens if total_tokens > 0 else 0.0 return avg_loss, avg_acc # ================================================ def stage_train(stages, config, resume=True): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") use_cuda = torch.cuda.is_available() # 尝试恢复检查点 checkpoint_state = None if resume: latest_checkpoint = find_latest_checkpoint() if latest_checkpoint: print(f"\n========== 恢复训练:{latest_checkpoint} ==========\n") tokenizer = ChatTokenizer(config) model = ChatModel(config) optimizer = AdamW(model.parameters(), lr=config["learning_rate"]) checkpoint_state = load_checkpoint(latest_checkpoint, model, optimizer, tokenizer, device) global_epoch = checkpoint_state["global_epoch"] start_stage_idx = checkpoint_state["stage_idx"] start_epoch_in_stage = checkpoint_state["epoch_in_stage"] print(f"从 epoch {global_epoch} 恢复训练\n") else: print("\n========== 未找到检查点,从头开始训练 ==========\n") checkpoint_state = None start_stage_idx = 0 start_epoch_in_stage = 0 # 如果没有恢复,初始化新的训练 if checkpoint_state is None: print(f"\n========== Tokenizer ==========\n") tokenizer = ChatTokenizer(config) tokenizer.build_split_tokens(stages) pad_id = tokenizer.get_split_tokens()["<|padding|>"] model = ChatModel(config) model.to(device) print(f"Using device: {device}\n") optimizer = AdamW(model.parameters(), lr=config["learning_rate"]) global_epoch = 0 start_stage_idx = 0 start_epoch_in_stage = 0 scheduler = CustomLRScheduler(optimizer, config) num_workers = min(16, os.cpu_count() or 1) # 只在 CUDA 可用时创建 GradScaler scaler = torch.amp.GradScaler() if use_cuda else None # 只在 CUDA 可用时启用 pin_memory pin_memory = use_cuda for stage_idx, stage in enumerate(stages): if stage_idx < start_stage_idx: continue print(f"\n========== {stage['stage_name']} ==========\n") dataset = ChatDataset(tokenizer, stage["file_path"], config) indices = torch.randperm(len(dataset)).tolist() split_idx = int(len(dataset) * (1 - config["split_valid"])) train_dataset = Subset(dataset, indices[:split_idx]) val_dataset = Subset(dataset, indices[split_idx:]) train_loader = DataLoader(train_dataset, batch_size=config["batch_size"], num_workers=num_workers, persistent_workers=(num_workers > 0), shuffle=True, pin_memory=pin_memory) # Validation: use num_workers=0 to avoid hanging on Windows with persistent workers val_loader = DataLoader(val_dataset, batch_size=config["batch_size"], num_workers=0, shuffle=False, pin_memory=False) # 确定当前stage的起始epoch current_start_epoch = start_epoch_in_stage if stage_idx == start_stage_idx else 0 for epoch_in_stage in range(current_start_epoch, stage["epochs"]): scheduler.step(global_epoch) model.train() train_loss, train_acc = run_epoch(model, train_loader, device, tokenizer.get_split_tokens()["<|padding|>"], global_epoch, optimizer=optimizer, scaler=scaler, use_cuda=use_cuda, accumulation_steps=config.get("accumulation_steps", 1)) model.eval() val_loss, val_acc = run_epoch(model, val_loader, device, tokenizer.get_split_tokens()["<|padding|>"], global_epoch, optimizer=None, scaler=None, use_cuda=use_cuda, accumulation_steps=config.get("accumulation_steps", 1)) save_path = os.path.join(".", f"{stage['stage_name']}_epoch_{global_epoch+1}") save_checkpoint(model, optimizer, tokenizer, config, global_epoch, stage_idx, epoch_in_stage, save_path) print(f"\n检查点已保存: {save_path}\n") global_epoch += 1 # ================================================ if __name__ == "__main__": parser = argparse.ArgumentParser(description="训练聊天模型") parser.add_argument("--resume", action="store_true", default=True, help="从最新的检查点恢复训练(默认启用)") parser.add_argument("--no-resume", action="store_false", dest="resume", help="不恢复训练,从头开始") args = parser.parse_args() torch.backends.cudnn.benchmark = True torch.backends.cuda.matmul.allow_tf32 = True stages = [ {"stage_name": "Fine-tuning", "file_path": "./data/daily_dataset_zh_filter.txt", "epochs": 12}, ] stage_train(stages, default_config, resume=args.resume) 训练python .\train.py ========== Tokenizer ========== [Tokenize 01]: 100%|█████████████████████████████████████████████████████████| 300001/300001 [00:56<00:00, 5267.13it/s] Using device: cuda ========== Fine-tuning ========== [Train 01]: 100%|████████████████████| 74250/74250 [2:31:09<00:00, 8.19it/s, loss=1.574882, acc=0.489533, lr=0.000100] [Valid 01]: 100%|██████████████████████████| 751/751 [01:09<00:00, 10.87it/s, loss=2.426748, acc=0.566438, lr=0.000000]推理chat.pyimport os, json, torch from safetensors.torch import load_file from train import * from collections import OrderedDict from colorama import init as colorama_init, Fore, Style colorama_init(autoreset=True) # ================================================ def sample_next_token(logits, generated_tokens, repetition_penalty, presence_penalty, temperature): for token in set(generated_tokens): if logits[token] < 0: logits[token] *= repetition_penalty else: logits[token] /= repetition_penalty vocab_size = logits.size(0) mask = torch.zeros(vocab_size, dtype=torch.bool, device=logits.device) mask[list(set(generated_tokens))] = True logits[mask] += presence_penalty probs = torch.softmax(logits / temperature, dim=-1) next_token = torch.multinomial(probs, num_samples=1) return next_token.item(), probs # ================================================ def generate_response(model, tokenizer, prompt, device, config, max_length=512, temperature=0.3, repetition_penalty=1.0, presence_penalty=-1.5): encoded = tokenizer(f"<|user|>{prompt}<|assistant|>", update=False) generated = encoded["input_ids"].unsqueeze(0).to(device) unknown_id = tokenizer.split_tokens.get("<|unknown|>") end_id = tokenizer.split_tokens.get("<|end|>") newline_id = tokenizer.split_tokens.get("\\n") print(Fore.GREEN + "Assistant:" + Style.RESET_ALL, end=" ", flush=True) with torch.no_grad(): for _ in range(max_length): if generated.size(1) > config["max_seq_length"]: current_input = generated[:, -config["max_seq_length"] :] pos_offset = generated.size(1) - config["max_seq_length"] else: current_input = generated pos_offset = 0 outputs = model(current_input, pos_offset=pos_offset) logits = outputs["logits"][0, -1, :].clone() gen_tokens = generated[0].tolist() token_id, probs = sample_next_token(logits, gen_tokens, repetition_penalty, presence_penalty, temperature) if token_id == unknown_id and probs.sum() > 0: probs[unknown_id] = 0.0 probs = probs / probs.sum() token_id = torch.multinomial(probs, num_samples=1).item() generated = torch.cat((generated, torch.tensor([[token_id]], device=generated.device)), dim=1) if token_id == end_id: break token_str = tokenizer.decode([token_id]) if token_id == newline_id: print() else: print(token_str, end="", flush=True) print() # ================================================ def load_chat_model(model_dir, device): with open(os.path.join(model_dir, "config.json"), "r", encoding="utf-8") as f: config = json.load(f) with open(os.path.join(model_dir, "tokenizer.json"), "r", encoding="utf-8") as f: token_dict = json.load(f) tokenizer = ChatTokenizer(config) tokenizer.split_tokens = OrderedDict(token_dict) model = ChatModel(config).to(device) state_dict = load_file(os.path.join(model_dir, "model.safetensors")) model.load_state_dict(state_dict) model.eval() print("=" * 50) total_params = sum(p.numel() for p in model.parameters()) print(f"Total parameters: {total_params:,}") return model, tokenizer, config # ================================================ if __name__ == "__main__": print("EasyGPT Beta V1.5 Torch Inference (Dev)") model_dir = "./Fine-tuning_epoch_15" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model, tokenizer, config = load_chat_model(model_dir, device) while True: print("=" * 50) prompt = input(Fore.CYAN + "User:" + Style.RESET_ALL + " ") if prompt.strip().lower() in ["exit", "quit"]: break generate_response(model, tokenizer, prompt, device, config) 推理一个epoch效果python .\chat.py EasyGPT Beta V1.5 Torch Inference (Dev) ================================================== Total parameters: 77,607,436 ================================================== User: 你好 Assistant: 当然,我可以帮您解决一个问题。 ================================================== User: 你怎么样 Assistant: 当我们遇到困难时,我们会遇到一些挑战和困难。以下是一些可能的方法: 1. 学习新技能和知识。通过阅读相关书籍、在线资源、参加社交活动等方式来学习新技能。 2. 练习写作技巧。使用专业术语或者词汇来帮助学生更好地理解文本。 3. 寻找新的学习资源。如果你想要写作,可以寻找一些有趣的学习资源。 4. 与同事合作。学习新的知识和技能也是提高自己的能力的重要因素。 5. 尝试不同的学习方式。不断尝试新的学习方式,并尝试新的教材和技巧。 6. 学习新的技能和知识。学习新的技能和知识,可以让你更快地掌握新技能和知识。 7. 学习新的技能和知识。学习新的技能和知识,可以让你更快地适应新的环境和技能。 8. 坚持学习。学习新技能和知识可以让你更快地掌握新技能和知识。 9. 学习新技能和知识。学习新技能和知识可以帮助学生更好地了解新技能和知识,从而更好地适应新的环境和变化。 总之,学习新技能和知识的重要性,需要不断努力和探索。 ================================================== User: 今天天气怎么样 Assistant: 1. 去散步或骑自行车 2. 穿上适合的衣服和鞋子,可以选择一些轻便的衣服或者是一种舒适的运动方式。 3. 在户外活动或户外活动中进行户外活动,如徒步旅行、爬山或徒步旅行等。 4. 在户外活动中放松身心,可以享受到美好的时光和休息。 ==================================================两个epoch效果python .\chat.py EasyGPT Beta V1.5 Torch Inference (Dev) ================================================== Total parameters: 77,607,436 ================================================== User: 你是谁 Assistant: 我是一个人工智能模型,没有感觉或情感。但是,我可以为您提供一些关于人工智能的信息和建议。 首先,我们需要了解人工智能的定义和应用场景。人工智能的目标是让计算机系统能够像人类一样思考、学习、推理和决策等方面的能力。这种技术包括语音识别、图像识别、自然语言处理、计算机视觉、语音识别、机器翻译等。此外,人工智能还可以通过机器学习来实现自动驾驶汽车、智能家居、医疗保健、金融服务等领域。 其次,人工智能也是一个非常重要的话题。人工智能在各行各业都有广泛的应用,如医疗保健、交通运输、制造业等。例如,在金融领域,人工智能可以帮助银行进行风险评估和投资决策。此外,人工智能还可以帮助企业更好地管理风险和预测市场趋势。 最后,人工智能也是一个非常热门的话题。人工智能的应用场景是使用自然语言处理技术,比如语音识别、机器翻译、智能客服等。人工智能的应用场景也很广泛,比如智能家居、智能家居等。 总之,人工智能已经成为人工智能领域的一个热门话题。它不仅可以帮助人们更好地理解人类生活,还可以为人类带来更多便利和高效的生活体验。 ================================================== User: 你好 Assistant: 我叫 EasyGPT,很高兴见到您。请问您想要咨询哪个职位? ================================================== User: 你是什么 Assistant: 我是一个人工智能模型,没有真实的感觉或情感。 ==================================================